.png)
Today we’re excited to announce the much-anticipated release of Python in the canvas! It’s clear Python is no longer a tool just for data scientists, but is highly valued in every part of the data stack.
Our aim in bringing Python cells into the canvas is to reflect the way data teams work: use the best language for the job at each point in time, while having the flexibility of the canvas to lay everything out at once, and the transparency to communicate that with others.
You can skip ahead and check out the documentation here, and an example Python canvas here, or keep reading to learn more.
Count has always been a SQL-first tool. We believed (and still do), that SQL is the primary language of data analytics, but over time we couldn’t deny the growing role Python was playing in data teams. SQL was the way you spoke to the database, but Python was getting used for so much more: pulling data from APIs, creating predictive models and forecasts, finding outliers, creating custom visualizations, etc., etc.
You could no longer separate SQL work from Python work. And we knew that in order to support data teams, we needed to support Python in the canvas.
Python cells in the canvas work similarly to DuckDB cells. (I encourage you to check out Jason’s article on our query architecture if you haven’t, he explains it in more detail than I will here.)
Each canvas has its own Python instance running locally in your browser using Pyodide. From this local instance, we install any packages and modules you import, and we execute any code you’ve written.

Running Python in the canvas is one thing, but we knew in order for Python to really make a difference, it had to work seamlessly with every other object in the canvas.
This means you can:

More than that, Python cells also work with Count’s reactive cell framework. This means:
Making Python cells a seamless part of the canvas allows teams to work as they do now and choose the right language for the job, without sacrificing flexibility, transparency, or functionality.
There are countless ways to use Python, so this is not an exhaustive list, but a reflection of the most common ways people are using Python in the canvas today.
You can check out this canvas to see these (and more) use cases in action.

While it would be great if all the data we needed had a nice, automated way to get into our data warehouse, that is usually not the case. We may need to use APIs to get information from services we use (e.g. Facebook Ads) or to pull in data we use as references (e.g. US Postcode boundaries).
To pull from APIs in the canvas, you can now:

You can see an example of how to pull data from an API in the canvas here.
Python is far better suited to do some of the complex analytical tasks we need to perform like forecasting, model-fitting, and text analysis (to name a few).
The example below shows an interactive way to fit a model for some time series data. You’ll notice:

Using functions or built-in methods can help immensely when doing data transformation. In the example below we’re converting a string column to an integer with some bespoke logic. We can then see the difference between the column before and after the distribution on either side of the Python cell.

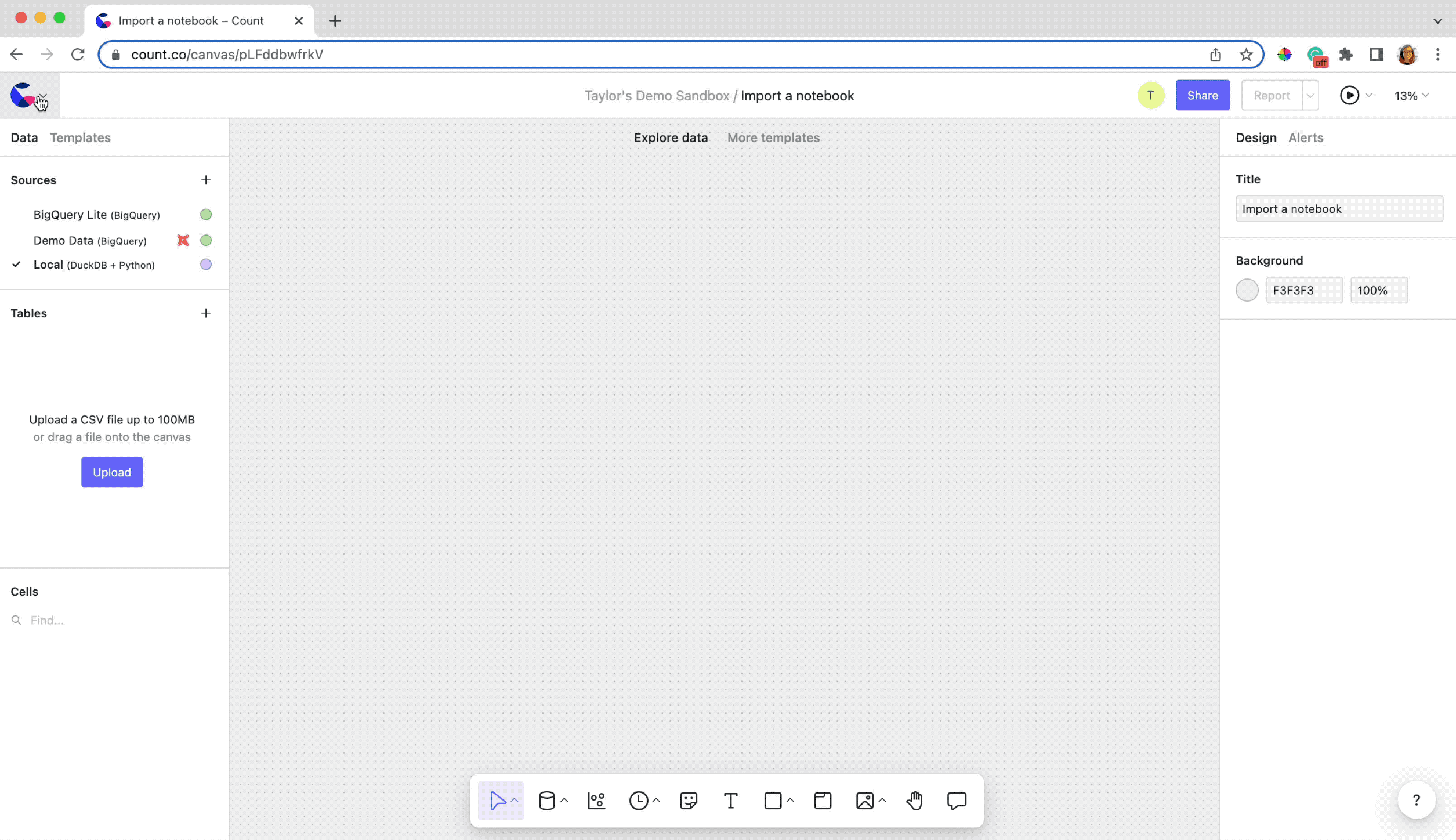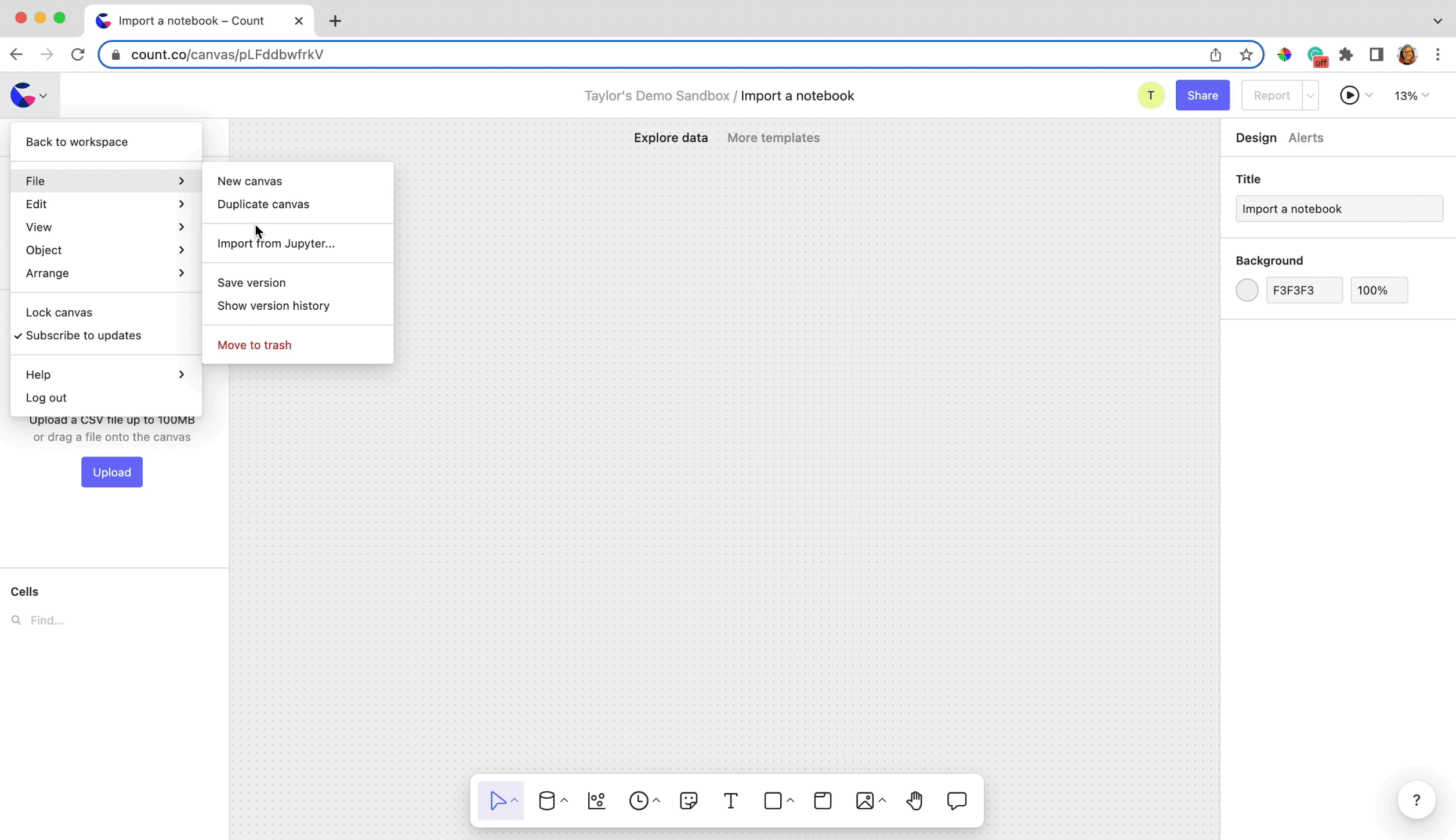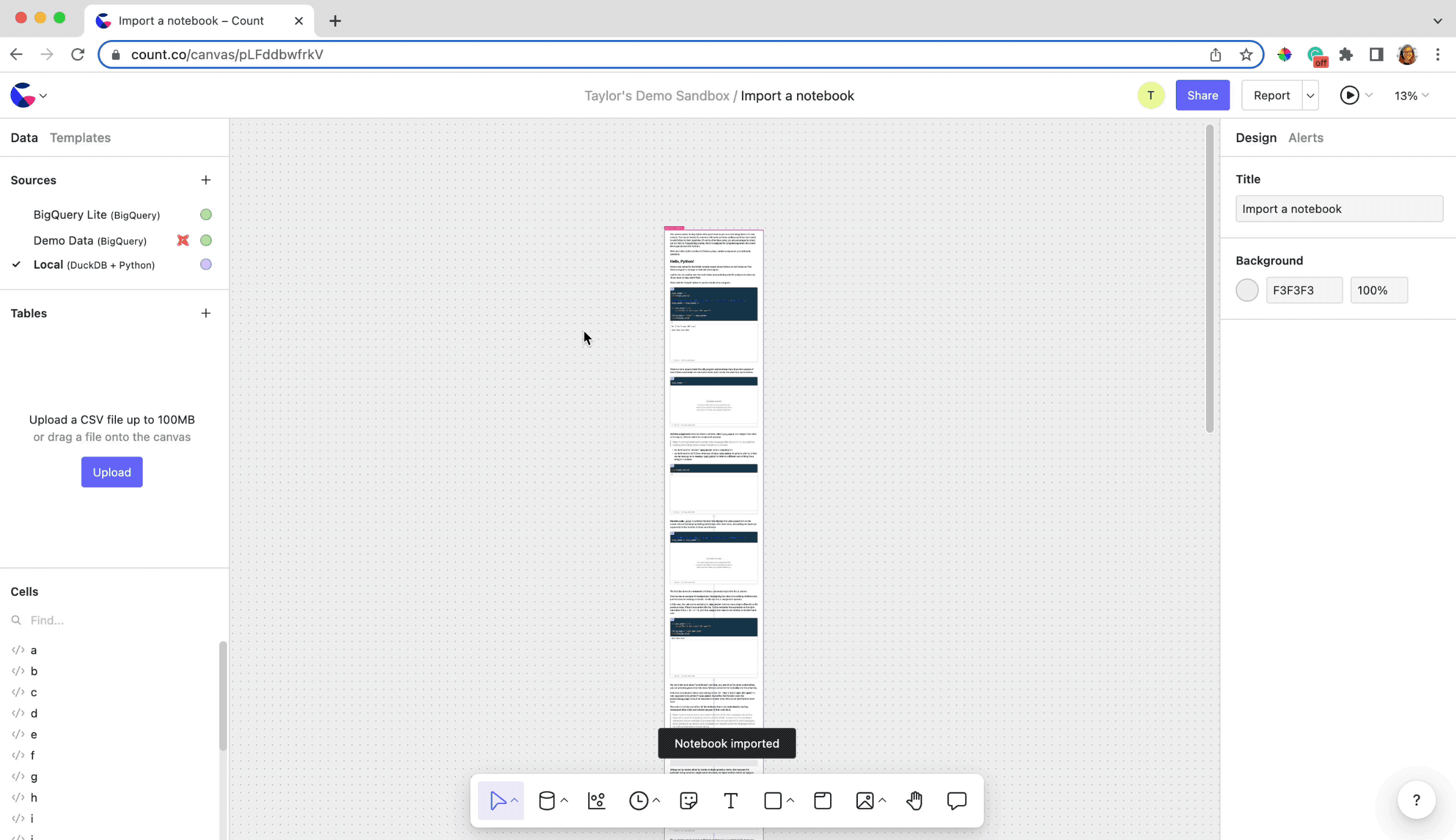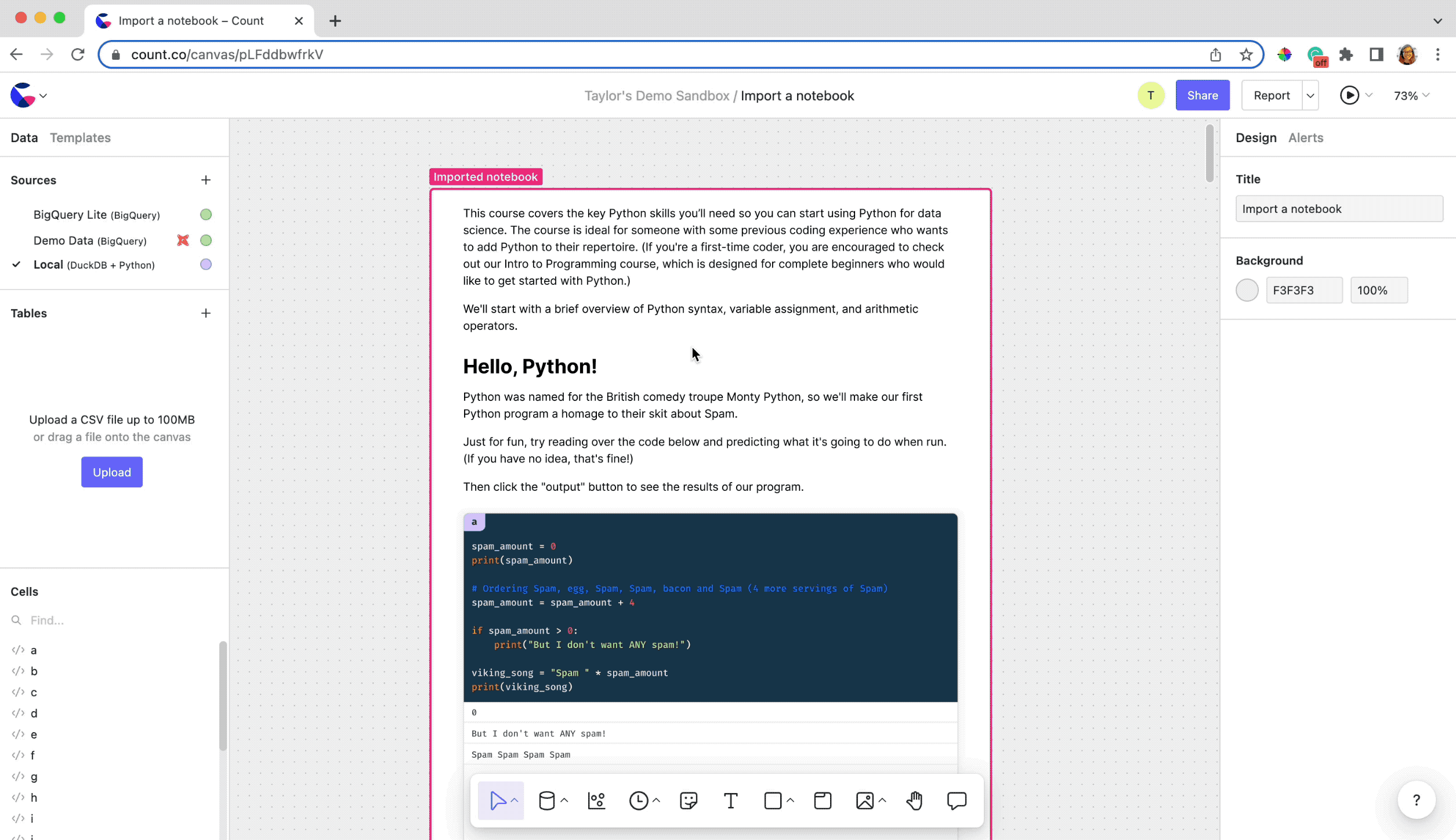
To get started with Python in the canvas, we suggest importing an existing Jupyter notebook you have:
Also, check out these resources:


