How to successfully deploy an analytics agent in 2 weeks or less
Written by Holly Traynor
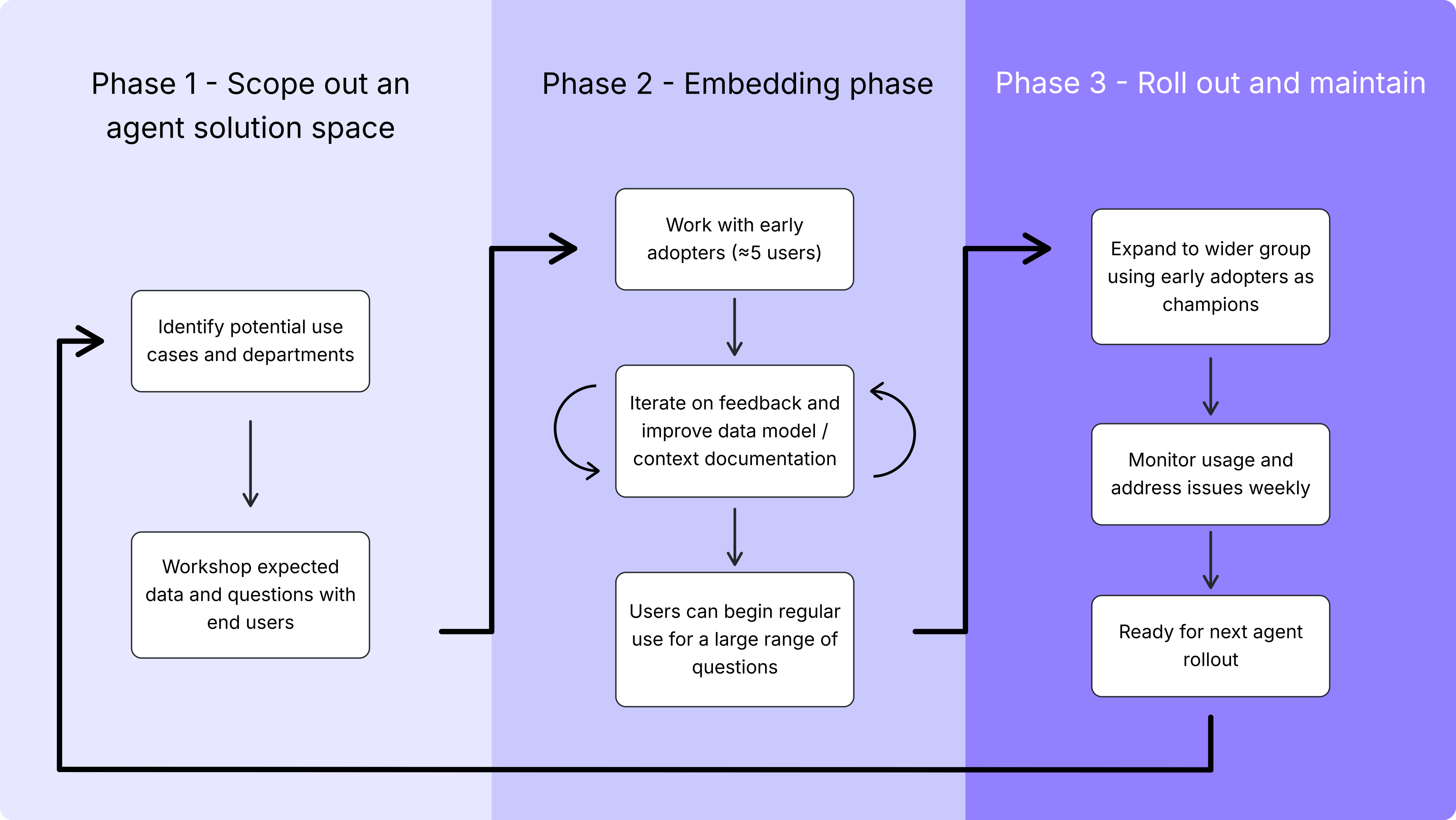
Holly Traynor shares a 3-phase playbook to deploy a trusted analytics agent in under two weeks, from scoping and embedding to guided rollout and scale.
We’ve talked about self-serve analytics for years, but never quite like this. With a growing wave of agentic solutions on the market, business users can now self-serve high-quality analysis in ways that simply weren’t possible before.
However, the challenge remains how we roll this new capability out successfully.
Having supported early adopters of our own agent, we’ve consistently heard the same concerns when it comes to rolling it out across the wider business:
- Lack of control - fear of what agents might do or recommend without guardrails
- Trust and accuracy - concern that one wrong answer could erode confidence quickly
- Accountability - uncertainty around who owns decisions influenced by an agent
- Exposing weak data foundations - inconsistent metrics and definitions don’t stay hidden for long
- Cultural and workflow changes - agents don’t just change tools, they change how work gets done
But the key to rolling out agents is no different to rolling out any other data product: start small and iterate:
- Scope - focus on use cases your team engage with regularly and avoid the trap of chasing edge cases.
- Build trust - let a small number of users test queries in a controlled environment to build trust. Watch how they interact with the agent, refine responses based on their feedback, and let early wins build confidence before expanding access.
- Deploy at scale - use your advocates to help embed the agent in the wider business. They become your credibility layer, helping new users understand what works and how to get value from the agent.
In this guide, we’re going to break down these three phases into practical advice we’ve learnt to help you deploy your agent confidently in two weeks.
Phase 1: Scope
Scope can make or break any data product - agents are no different. You want a scope focused enough to deliver value but broad enough to matter.
Going too narrow leads to trivial insights and inability to help drive decisions, whilst going too broad will slow down time-to-value & increase likelihood of failure from complex transformations across multiple data sources.
Particularly if this is your first agent roll out, having a tight, well-defined scope increases the chances that the product actually gets used, delivers value and can be iterated on efficiently.
To build a solid scope, focus on these questions:
- What decisions do people need to make with data?
- This will ensure you build something that is needed and adds value.
- What data do we need to facilitate these decisions?
- You may have existing data models that can drive these decisions, consider these before duplicating work!
- Who will be making the decisions?
- Each department has its own questions, data maturity, and tolerance for change, which is why starting with one department is a powerful way to scale adoption without losing trust.
- Identify users in this group of decision makers to help you test. We recommend 3-5 users who make decisions frequently and represent the core persona to ensure you can pick up on repeated behaviour.
These questions, and usage data from existing data assets, will give you a great starting point on where to focus but more details will come from running a workshop with the identified end-users to iron out the details and ensure what you assume they will find valuable is true. A lot of time can be wasted from not including the end-users in the scope!
Once you have a well-defined scope that everyone is aware of and agrees on, you can start the embedding phase.
Phase 2. Embedding (1-2 weeks)
The embedding phase is the foundational work for a successful rollout. It focuses on iterating and optimising until you have an agent that you are confident drives value.
It’s a chance for your early adopters to really put the agent to the test, give feedback and know the agent is driving real value before it’s fully launched. This period also provides a low risk way for you to understand and solve any governance issues, cost implications (e.g. how many credits are used) and get a handle on the best way to maintain the agent when it’s operating at scale.
Set expectations with early adopters:
One of the most important parts of a successful embedding phase is to set expectations well with your early adopters. They are there to help you make the agent great which may take a week or so. It’s good to remind them:
- The agent isn’t perfect - the embedding phase exists to ensure any governance and data issues are ironed out ahead of a wider rollout. Remind early users to expect friction, but that mistakes and issues will be ironed out quickly.
- The output of any agent is only as good as the data you give it - you want to ask enough questions to understand the breadth of use cases the agent will face, and to make sure the outputs are accurate. Any gaps or issues in the data or models can be addressed here.
- Prompts matter - make sure you are clear, detailed and explicit when asking an agent a question. It’s very clever but it can’t read minds!
Testing the agent:
Remember your scope! The early adopters should focus on testing the agreed scope to ensure the feedback is relevant and actionable.
We’d recommend working with three to five early users to test the agent for several days (or at least 5-10 questions each to ensure breadth) with daily retros to test the breadth of use-cases and collate feedback (they could even record themselves using it for more thorough feedback!).
At this point, it’s right to spend time training users, push them to write detailed prompts and ask a range of questions. As they get comfortable and confident you should see them asking questions you didn’t expect which the data team can then iterate on before testing again.
You’ll repeat this process until you’re confident the agent is proving value.
Run a retro —> collate feedback —> iterate on the data model and/or agent context —> users test again
In addition to receiving feedback regarding their experience using the agent, the embedding phase is also a pilot for the wider implications of using an agent, so it’s important to capture these too (e.g. changes to workflow, what usage looks like compared to the credits you have available).
These retros will become redundant for one of two reasons:
- users aren’t having issues anymore —> time for wider rollout
- users have stopped using the agent —> revisit your scope to ensure you got the right use-case
By the end of this phase, you’ll have an agent you’re confident in, worked through any governance and cost implications, and acquired strong advocates to help you rollout the agent to a wider audience.
Phase 3: Guided roll-out & maintenance
Now you have your agent, a strong set of initial advocates and a data model you’re confident in. At this point, you can safely rollout to the wider team. But as a reminder - don’t forget your scope!
Refer back to your original scope and guide the rollout to match. Make sure your end-users are clear on:
- Why the agent exists. What decisions has it been built to help with?
- What data is available to query. This is an early iteration that will evolve over time, explain what data is currently available to use and allow for feedback on what they’d like moving forward - this will set expectations and let them know what to expect.
Your early adopters are a crucial resource in the rollout, they can help up skill end-users and should be on hand to ask questions while the wider team is getting up to speed.
The power of agentic analytics evolves as the underlying data models are improved through end-user feedback on the types of questions they want to ask, and keeping it effective requires ongoing attention. All of the foundational work in the embedding phase should mean that monitoring becomes much lighter, however some key principles are:
- Monitor usage and accuracy
- Refine data models and prompts continually
- Maintain governance with trusted metrics
- Share wins to build momentum
- Scale agent autonomy gradually while keeping humans in the loop
The goal is to turn agentic analytics from a novelty into a trusted, integral part of decision-making; a tool that improves both speed and quality of insight across the organization.
Organizational rollout
Once you’ve successfully rolled out to one team, you can take the learnings from that and roll out more agents across your organization using the same stages as outlined above:
- Scope
- Embed
- Rollout & maintain
Depending on your capacity and organizational size, you can stagger rollouts by department or run them in parallel.
As you repeat the process, it becomes increasingly predictable and scalable, ultimately ensuring that everyone across the organization has access to an agent that measurably improves daily decision-making.