How we made data modeling multiplayer
Written by The Count Team
Collaborate on data models with Count's new dbt Core integration—streamline workflows, enhance visibility, and simplify data exploration.
Today we’re excited to announce the launch of our dbt Core™integration, making Count the most collaborative way to build data models.
Data modeling and analytics are two sides of the same workflow and suffer similar pain points: single-player, multi-tool workflows which are hard to audit and understand, and make it difficult for the data team to work effectively with the wider business.
Over the last 12 months, we’ve built Count to be the most advanced and collaborative tool for data exploration and storytelling. Every day hundreds of data teams rely on Count to simplify their workflow, build analysis collaboratively, and solve the biggest problems facing their business.
But during the last year, we’ve watched our customers using Count not just for analytics, but as a way to collaborate and simplify their data modeling workflow too. Six months ago we launched our dbt Cloud integration to allow our users to bring their dbt models into the canvas. Today we’ve gone a step further with dbt Core support and a huge upgrade to our dbt Cloud integration.
With these upgrades, you can now:
- Get full visibility of your pipelines by importing all of your models with.
- Write queries using familiar dbt macros and Jinja syntax,to view results instantly.
- to examine the results of individual CTEs.
- together to write code, debug models, and iterate logic.
- , and commit changes or open pull requests directly from the canvas.
You can learn more about the new dbt integrationsin our docsor by watching the demo video below.
But what are the challenges involved with integrating Python-native dbt into a collaborative React web application without impacting performance? In the rest of this article, we’ll be digging into some of the interesting problems we had to solve to build the first truly collaborative data modeling experience!
Our dbt Cloud integration allowed importing the compiled SQL for any model, but we knew we had to go further - both for dbt Cloud users and also to support the workflow for our users using dbt Core. Specifically, this meant:
- Allow loading a dbt project from any branch of a GitHub repository.
- Allow import and navigation of the full project, scaling to many hundreds of models and beyond.
- Allow writing models with full Jinja and macro support, with rapid compilation for tight feedback loops.
- Allow committing changes directly back to the dbt project with confidence.
These requirements created a number of challenges for us. Unlike dbt, Count is a fully reactive, real-time collaborative environment. From the start, this meant that we had to think carefully through our implementation to ensure:
- Rendering performance in the canvas needs to remain high - think hundreds of cells at 60FPS.
- Compilation of Jinja needs to have very low latency.
- Edits to cells need to be reactive and support all existing Count features.
Let's take a technical deep-dive into how we implemented our dbt Core integration under these constraints, leveraging our previous work onPythonandJinjasupport in the canvas.
We'll work through the implementation of the following simple user story:
Import raw Jinja-templated code from GitHub, and execute it in a Count cell.
Given our performance and latency constraints, we decided to perform the Jinja compilation locally in the in-canvas Python process. This keeps performance sufficiently high that Jinja compilation can be seamlessly weaved into the existing reactive canvas DAG.
The above story can be broken into sequential steps that need to be executed when, for example, opening a canvas:
- Get the model and macro definitions from your dbt project
- Compile the macros into executable Python objects
- Compile the Jinja template into plain SQL
In the following sections, we'll walk through the details involved in each step.
Understanding your dbt project
One of our first priorities was to extract and surface as much information as possible from your dbt project. We landed on a generic approach where the common input to all of our dbt import logic was yourartifactfiles. These files are generated automatically by dbt and contain all of the information about your models, tests, and macros.
We could retrieve these files from dbt Cloud, generate them from a GitHub repository, or they could be uploaded manually.
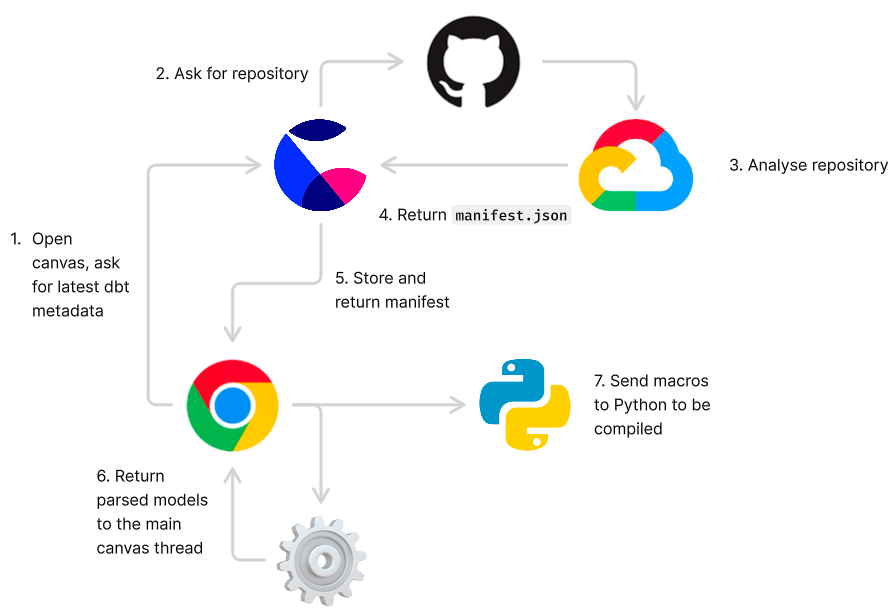
To illustrate how this works, consider the situation where you've asked for dbt metadata to be generated for some branch in GitHub:
The first part of the process is to download that branch and analyse it, which involves negotiating the various permissions required to access your repository. Assuming we're permitted to go ahead, we generate amanifest.jsonartifact in a temporary cloud VM and return it to you (and save a copy for later).
At this point we encountered our first clash with our performance requirements - some manifest files could be large, and parsing and validating them could cause visible rendering degradation in the canvas.
We therefore moved all of the artifact fetching and processing to its ownWeb Workerso that the main canvas thread could continue rendering unimpeded. We use theio-tslibrary to validate these JSON files and decode them into a common format abstracted across dbt versions.
Compiling macros
We receive macros from dbt as their raw source code - before they can be used they need to be compiled into executable Python objects.
Unsurprisingly at this point, we encountered a second performance issue - for some large projects with lots of dependencies, there might be thousands of macros to compile. As the Python process is the same one that executes Python cells, this parsing might block your Python queries from executing.
The Python language helped us here by making it possible to override the appropriate method on the macro object that we place in the Jinja compilation context - schematically, our macros are wrapped like the following which allows them to be compiled only when they're needed:
class LazyMacro:\n def __init__(\n self,\n definition: str,\n compile_macro: Callable[[str], JinjaMacro],\n ):\n self.compile_macro = compile_macro\n self.macro: JinjaMacro | None = None\n\n def __call__(self, *args: Any, **kwargs: Any) -> Any:\n if self.macro is None:\n self.macro = self.compile_macro(self.definition)\n\n return self.macro(*args, **kwargs)
💡
Writing Python 3.11+ with type hints alongside the VSCode Pylance extension is a great experience that feels very similar to Typescript.
One complexity to manage here is that macros need to know about the existence of each other,even if they haven't been compiled yet. They also need to be aware of other global dbt built-in macros such asref(). This context is all wrapped up ahead of time in thecompile_macrocallable closure scope, which allows us to define stable object references once and then rely upon them at any time later on.
Compiling Jinja
Jinja is a surprisingly fully-featured language in its own right, featuring:
- Function definitions
- Control flow
- Variable definitions
- Full Python syntax support
Our approach when compiling it is therefore to interfere as little as possible, and instead apply the behavior we need at the boundary of compilation - namely in the variables we inject into the Jinja compilation context.
One difficulty we encountered was related to our overall application structure. Count is rendered usingReact, which works best when all of the application state is stored on the main thread and updated synchronously. Unfortunately for us the Jinja compilation step is performed off-thread but needs information stored in memory on the main thread.
We therefore needed to make our Jinja compiler fully asynchronous, such that when information is required from the main thread it can be requested and awaited. There is also then no synchronization requirement between the main and compilation threads, as information is pulled into the compiler on-demand.
Referring to the diagram below, when compiling a simple Jinja expression several messages are exchanged between the two threads. While the compiler is waiting for a response it suspends execution, and we perform compilation in a blocking queue to ensure that compilation requests aren't interleaved.
This strict decoupling of logic between the compiler and the main thread also makes it simpler to modify the behavior of macros such asref()- for example, when referring to a cell the result of the compilation is different from when referring to a model.
This decoupling is also helpful when maintaining the DAG in Count, which must be larger and more generic than the dbt model DAG - the main canvas thread can keep track ofref()resolutions, and use that information to (for example) render the connector lines between cells.
It's also worth noting that the same messaging mechanism is used for therun_query()macro too (amongst others) - in this case, the query is dispatched on the main thread just like any other SQL query in Count.
As is evident here, the Jinja compilation process can be quite involved to set up and orchestrate, but thankfully our performance mitigations mean that is it very quick in practice, and it's not a problem to compile hundreds of cells.
The future
While it's been a lot of fun (and a challenge!) getting dbt models running in Count, we're aware this is just the beginning and there's lots more we can do. Potential directions include:
- Allow editing project macro definitions with reactive updates.
- Allow editing of YAML files in addition to model files.
- Presenting more model metadata directly in the canvas.
If you use dbt and have thoughts on where we should go next, please let us know! You can contact us using the in-app chat, or join theSlack communityand propose new features alongside lots of other Count and dbt fans.
If you've enjoyed reading this article and like to solve problems like these with Typescript,we're hiring!Please get in touch at jobs@count.co to learn more.
dbt™ is the emerging industry standard platform for analytics engineering in the modern data stack. It is used by thousands of companies including JetBlue, HubSpot, and Cisco, as well as data teams at startup and growth-stage companies. The dbt Community is one of the most active developer Slack communities and hosts Meetups on five continents. dbt, dbt Core, and dbt Cloud are trademarks of dbt Labs, Inc.