A study of embedded analysts
Written by The Count Team

Explore the benefits and challenges of embedded analysts with insights from Jurien Groot, enhancing data-driven decisions at Protolabs.
Embedded analysts: An interview
RecentlyJurien Groot, Head of Analytics at Protolabs, a Global Distributed manufacturer of low-volume, custom parts for prototyping and short-run productions, sat down to talk us through how he runs a central analytics team with embedded analysts across the business.
As a reminder, embedded teams are those in which the analysts (sometimes other roles too) sit within the business teams they support. There is only a dotted line connecting them to the central data team:
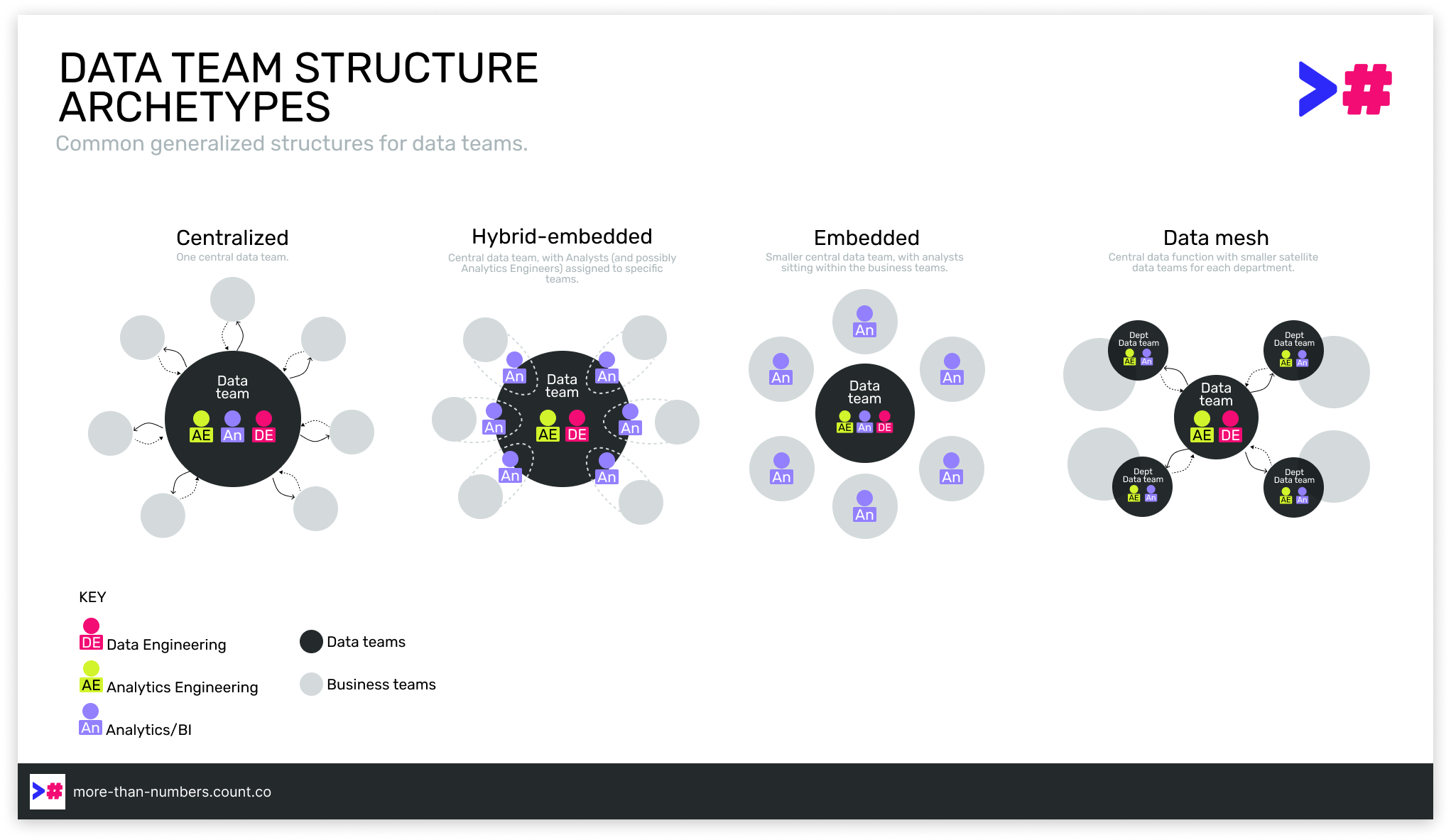
Embedded teams aren’t too popular at the moment, but with more and more teams handling limited budgets and cost-savings, there is a newfound curiosity:
“I’m always wondering if having analysts embedded is the right approach, espeically after some recent cuts. We don’t have enough analysts for each to work closely with one team anymore, so each has to service multiple teams at once. I’m not sure if that’s the right approach now that we’re so lean.” - Anonymous
Theory vs. reality
When you start talking to people about data team structures, you hear a standard set of tradeoffs when discussing embedded analysts:
Pros:
- : the data team doesn’t have to pay for the headcount of these analysts
- : a lot of the ‘Hey, give me those numbers’ requests go to the embedded analyst so that the central team can focus on more foundational things
- : there is a common argument that data is best in the hands of the subject matter experts since they have all the context and knowledge to make it useful
- : since data isn’t hidden behind another team’s walls, business teams are more likely to trust in numbers and welcome data whole-heartedly
Cons:
- without a centralized presence it’s difficult to scale common activities, or even have visibility into those common activities
- : it’s easy for embedded analysts to get isolated and not have a data identity
- : since a data leader is a dotted line manager at best in this context, it’s hard to have much say in what embedded analysts do
- : There is less oversight into what each analyst is doing, so it’s easy for things to be done ‘incorrectly’ without realizing it for a while
But that is just theory. Before you know know if the embedded approach is really one that’s worth trying, it’s best to hear from someone living it:
Q&A with Jurien Groot
We have a central data team with 2 analysts and 2 analytics engineers. Then across the business, 21 Data Gurus (embedded analysts) work within different teams on a group of 280 employees (Protolabs Network).
Initially, a Kahoot company quiz was held around analytics to get a grasp of who had some confidence with KPIs and analytical concepts. We also talk with the director for each team to work out (1) for which team members are analytics a natural component of the job, and (2) for those members, who are skilled enough to become a data guru.
We tend to rotate the data guru role within a team if the former data guru lacks commitment or has too many other priorities.
Each Data Guru is managed by one of the analysts on my team. We meet with them at least once every 2 weeks. The analyst is in charge of cascading the input of the data guru to our project board and aligning priorities with the directors. The analysts are responsible to educate and coach the data guru to become self-sufficient where possible.
We also have a robust review process, which we call a. During this time, we score each Guru on a scale of 1 to 5. We also score their department to work out how data-driven that department should be. For example, marketing is a level 5, they need to be very data-driven, so they need a Data Guru at least at a level 5. If the marketing data Guru is below a 5 then we step in and help that Guru up-skill with training, or doing working sessions together.
Some departments work well with a Data Guru at a level 2 or 3 though - it just depends on what’s needed.
We meet with each department lead once a month set the expectations and projects for that month, and decide what the Data Gurus will work on.
It’s expected that Data Gurus spend 20% of their time on analytics, and the rest is spent on the other parts of their job. So ideally at the start of the month, we have a rough idea of the major projects they work on, but it’s still up to their department leads what exactly they work on.
If at the end of the month, we look back and see they didn’t work on what we discussed, we’ll talk about it and see if it was something we could’ve predicted and can correct for in the future.
In terms of tasks and responsibilities, the data guru:
We run regular trainings with Data Gurus and host socials with the central analytics team and the Data Gurus. We also work closely with Data Gurus on their work - it’s common for them to ask for help on certain things or ask for advice on a certain approach.
There are some cases where a Data Guru loves the analytics part of the job and ends up joining us on the main team so they can commit to analytics full-time. It is nice that there is a career progression for them. They can grow in their departments to become product managers for example, or join us and work their way up to senior analysts or move into another data domain.
The first is domain knowledge. Data Gurus are domain experts, and we’ve seen great results by trusting them with data more and more. On a centralized team, you are in a reactive position where you wait for the requirements to be spec’d properly. Then have more back and forth with that department to deliver the project to meet their needs. There’s not a proper dialogue. Whereas our embedded analysts feed us with so much domain knowledge constantly that there’s a much more mature conversation about how we’re here to solve problems and not create reports.
The second is workload. We get to focus on the foundations - the pipelines, the data quality. We hardly ever get that request ‘I need a report tomorrow’ because that’s never on us (except from top management who don’t have their own data guru).
The big challenge at the moment is if the Data Guru doesn’t have time to work on something, that falls back on us, and we rarely have time to do those things either.
Another challenge is keeping the data gurus educated on the latest developments in our pipelines. New data is being added every month, definitions are updated and it can be challenging to keep up.
People can take it for granted that the data keeps flowing and is reliable. That’s why we make sure we’re adding value with our advanced analyst capabilities as a data team too. This is a skill our embedded analysts don’t have and can make a big impact on the business.
We are a data-driven organization, so it is a no-brainer that there is a data need in each team and a data guru is of huge value to everyone. Make sure you get support for this setup from the Management Team, they can promote the importance of well-educated data gurus.
A few reflections
It can be easy for data leaders working within an embedded model to take a passive approach to managing these roles, but what I admire about Jurien’s approach is how active he is. He and his team have carved out a significant amount of time and energy into making sure those embedded analysts are being as effective as they need to be.
The practice of calibrations he mentioned is an excellent representation of this. Regularly sitting down with business leaders to work out how they can be more data-driven is something every data leader should do, but is particularly effective when you need to lead via influence, not direct authority as is the case in an embedded model.
Moreover, the commitment to training Data Gurus to make sure they have all the information and support they need helps not just ensure they’re effective, but also that they feel part of the larger data team.
I think Jurien’s example is one many other teams could follow, especially if they are facing the realities of reduced headcount and budget.